code

I think move fast and break things is fine for many features. But the first step is identifying what you cannot break. These are things like billing code (as much as I'd like to, I probably shouldn't accidentally charge you a million dollars and then email you later with an "oops, sorry!"), upgrades (hardware or software upgrades can always be really dicey to perform), and data migrations (it's usually much harder to rollback data changes).
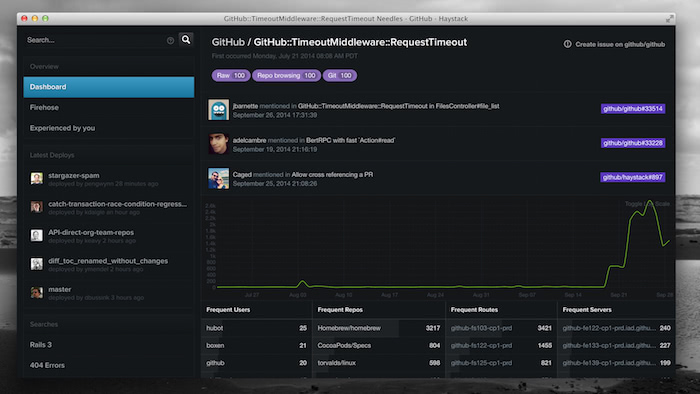
The last two years we've been upgrading GitHub's permissions code to be faster, safer, cleaner, and generally better. It's a scary process, though. This is an absolute, 100% can't-ever-break use case. The private repository you pay us for can't suddenly be flipped open to the entire internet because of a bug in our deployed code. 0.02% failure isn't an option; 0% failures needs to be mandatory.
But we like to move fast. We love to deploy new code incrementally hundreds of times a day. And there's good reason for that: it's safer overall. Incremental deploys are easier to understand and fix than one gigantic deploy once a year. But it lends itself to those small bugs, which, in this permissions case, is unacceptable.

So tests are good to have. This is unsurprising to say in this day and age; everyone generally understands now that testing and continuous integration is absolutely critical to software development. But that's not what's at stake here. You can have the best, most comprehensive test suite in the world, but tests are still different from production.
There are a lot of reasons for this. One is data: you may have flipped some bit (accidentally or intentionally) for some tables for two weeks back in December of 2010, and you've all but forgotten about that today. Or your cognitive model of the system may be idealized. We noticed that while doing our permissions overhaul. We'd have a nice, neat table of all the permissions of users, organizations, teams, public and private repositories, and forks, but we'd notice that the neat table would fall down on very arcane edge cases once we looked at production data.

And that's the rub: you need your tests to pass, of course, but you also need to verify that you don't change production behavior. Think of it as another test suite: for better or worse, the behavior deployed now is the state of the system from your users' perspective. You can then either fix the behavior or update your tests; just make sure you don't break the user experience.
Parallel code paths

One of the approaches we've taken is through the use of parallel code paths.
What happens is this: a request will come in as usual and run the existing (old) code. At the same time (or just right after it executes), we'll also run the new code that we think will be better/faster/harder/stronger (pick one). Once all that's done, return whatever the existing (old) code returns. So, from the user's perspective, nothing has changed. They don't see the effects of the new code at all.
There's some caveats, of course. In this case, we're typically performing read-only operations. If we're doing writes, it takes a bit more smarts to either write your code to make sure it can run both branches of code safely, or you can rollback the effects of the new code, or the new code is a no-op or otherwise goes to a different place entirely. Twitter, for example, has a very service-oriented architecture, so if they're spinning up a new service they redirect traffic and dual-write to the new service so they can measure performance, accuracy, catch bugs, and then throw away the redundant data until they're ready to switch over all traffic for real.
We wrote a Ruby library named Science to help us out with this. You can check it out and run it yourself in the github/dat-science repository. The general idea would be to run it like this:
science "my-cool-new-change" do |e|
e.control { user.existing_slow_method }
e.candidate { user.new_code_we_think_is_great }
end
It's just like when you Did Science™ in the lab back in school growing up: you have a control, which is your existing code, and a candidate, which is the new code you want to introduce. The science block makes sure both are run appropriately. The real power happens with what you can do after the code runs, though.
We use Graphite literally all over the company. If you haven't seen Coda Hale's Metrics, Metrics Everywhere talk, do yourself a favor and give it a watch. Graphing behavior of your application gives you a ton of insight into your entire system.
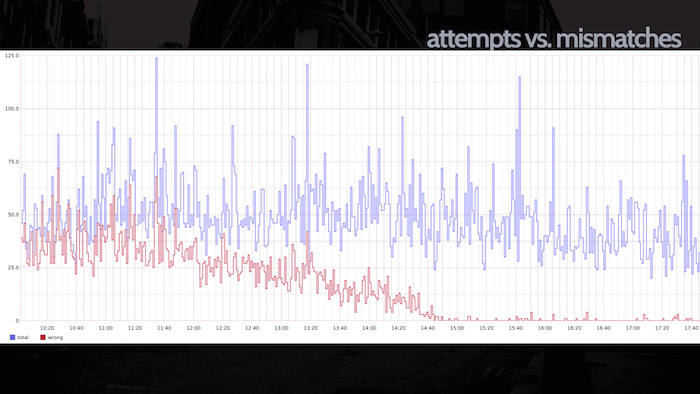
Science (and its sister library, github/dat-analysis) can generate a graph of the number of times the code was run (the top blue bar to the left) and compare it to the number of mismatches between the control and the candidate (in red, on the bottom). In this case you see a downward trend: the developer saw that their initial deploy might have missed a couple use cases, and over subsequent deploys and fixes the mismatches decreased to near-zero, meaning that the new code is matching production's behavior in almost all cases.
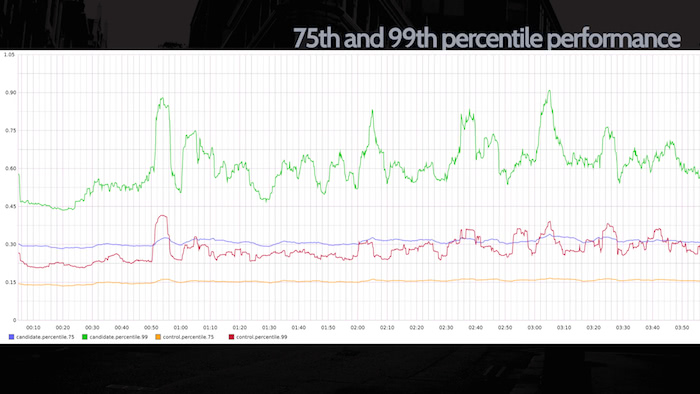
What's more, we can analyze performance, too. We can look at the average duration of the two code blocks and confirm if the new code we're running is faster, but we can also break down requests by percentile. In the slide to the right, we're looking at the 75th and 99th percentile, i.e. the slowest of requests. In this particular case, our candidate code is actually quite a bit slower than the control: perhaps this is acceptable given the base case, or maybe this should be huge red sirens that the code's not ready to deploy to everyone yet... it depends on the code.
All of this gives you evidence to prove the safety of your code before you deploy it to your entire userbase. Sometimes we'll run these experiments for weeks or months as we widdle down all the — sometimes tricky — edge cases. All the while, we can deploy quickly and iteratively with a pace we've grown accustomed to, even on dicey code. It's a really nice balance of speed and safety.
build into your existing process
Something else I've been thinking a lot about lately is how your approach to building product is structured.

Typically process is added to a company vertically. For example: say your team's been having some problems with code quality. Too many bugs have been slipping into production. What a bummer. One way to address that is to add more process to your process. Maybe you want your lead developers to review every line of code before it gets merged. Maybe you want to add a layer of human testing before deploying to production. Maybe you want a code style audit to give you some assurance of new code maintainability.
These are all fine approaches, in some sense. It's not problematic to want to achieve the goal of clean code; far from it, in fact. But I think this vertical layering of process is really what can get aggravating or just straight-up confusing if you have to deal with it day in, day out.

I think there's something to be said for scaling the breadth of your process. It's an important distinction. By limiting the number of layers of process, it becomes simpler to explain and conceptually understand (particularly for new employees). "Just check continuous integration" is easier to remember than "push your code, ping the lead developers, ping the human testing team, and kick off a code standards audit".
We've been doing more of this lateral process scaling at GitHub informally, but I think there's more to it than even we initially noticed. Since continuous integration is so critical for us, people have been adding more tests that aren't necessarily tests in the classic sense of the word. Instead of "will this code break the application", our tests are more and more measuring "will this code be maintainable and more resilent towards errors in the future".

For example, here are a few tests we've added that don't necessarily have user-facing impact but are considered breaking the build if they go red:
- Removing a CSS declaration without removing the associated
classattribute in the HTML - ...and vice versa: removing a
classattribute without cleaning up the CSS - Adding an
<img>tag that's not on our CDN, for performance, security, and scaling reasons - Invalid SCSS or CoffeeScript (we use SCSS-Lint and CoffeeLint)
None of these are world-ending problems: an unspecified HTML class doesn't really hurt you or your users. But from a code quality and maintainability perspective, yeah, it's a big deal in the long term. Instead of having everyone focus on spotting these during code review, why not just shove it in CI and let computers handle the hard stuff? It frees our coworkers up from gruntwork and lets them focus on what really matters.
Incidentally, some of these are super helpful during refactoring. Yesterday I shipped some new dashboards on github.com, so today I removed the thousands of lines of code from the old dashboard code. I could remove the code in bulk, see which tests fail, and then go in and pretty carelessly remove the now-unused CSS. Made it much, much quicker to do because I didn't have to worry about the gruntwork.
And that's what you want. You want your coworkers to think less about bullshit that doesn't matter and spend more consideration on things that do. Think about consolidating your process. Instead of layers, ask if you can merge them into one meeting. Or one code review. Or automate the need away entirely. The layers of process are what get you.