Look, I don’t give two shits about my Git commits.
I have no shame — okay, maybe a little shame — dropping these commits into my repositories:
Over the last five years, I’ve gotten a lot of questions along the lines of “should I rebase my branches or deal with a merge commit or maybe even squash all of my commits down into a single commit before merging?” Like most pedantic programmer debates, my answer is usually “I don’t care, I’m going to grab another slice of pizza, you do you”, but I’ve been thinking about this a lot recently and I think there’s a more interesting question to consider instead:
Why do developers take different approaches to repository histories?
A tale of two changes
My favorite commit author of all time is Jeff King (@peff). I like his commits so much that even if I were the Sepp Blatter of the Commit Olympic Committee, I wouldn’t need to be bribed to nominate him as a finalist. He’s the number two committer to Git itself, and his commits are truly lovely to read. More often than not, the diff may only be a couple of lines but he’ll likely include a detailed, multi-page writeup with code examples and performance benchmarks in the commit message.
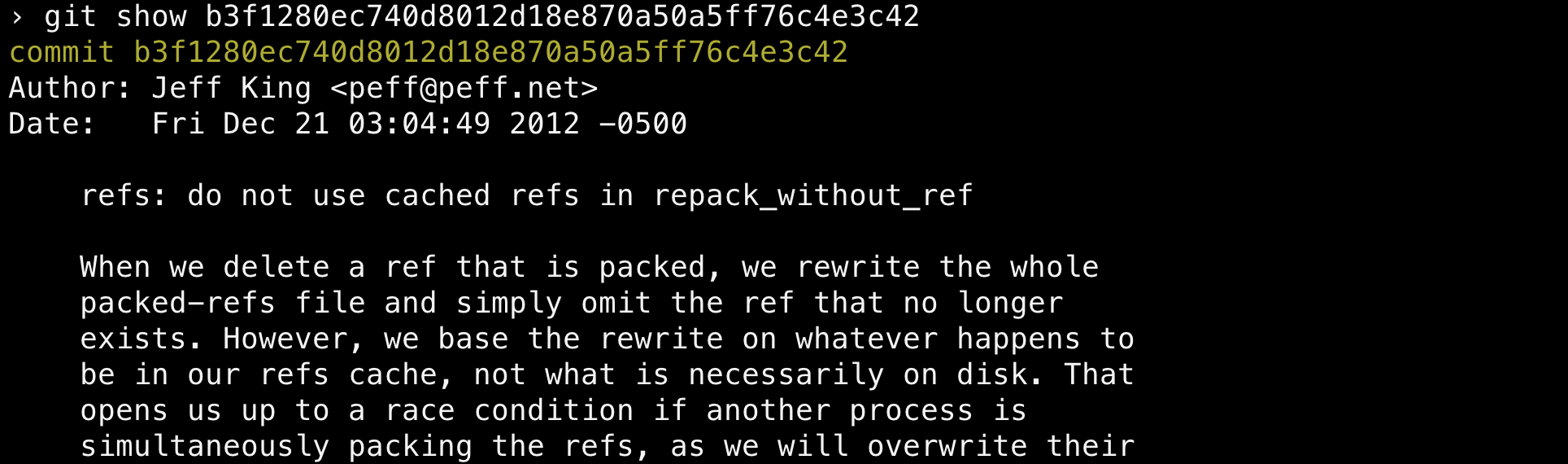
This works for git-core because their unit of change is at the commit level. Each commit is designed to be a comprehensive, standalone measurement of the change introduced into the repository. This is a byproduct of their process: contributors are to use git format-patch and git send-email to send their patches to the mailing list so that changes can be efficiently reviewed, discussed, and merged to master.
Git’s maintainers would say this commit process is designed to ensure speed, quality, and safety. They should know; they’re the best example of working efficiently within Git.
On the flipside, GitHub is the best example of how to work within github.com, and if you ask them, they’d probably defend their process with the exact same rationale: it allows them to move with speed, quality, and safety. Every single change enters production via a pull request, and as such, the pull request is king… not necessarily the commit.
Nathan Sobo (@nathansobo) is one of my favorite pull request authors. It’s an egregious example for the sake of illustration, but take a look at this particular commit on the Atom repository. It’s a fairly stereotypical commit for GitHubbers: hell, even the commit message itself is emoji. This would not get accepted in git-core.
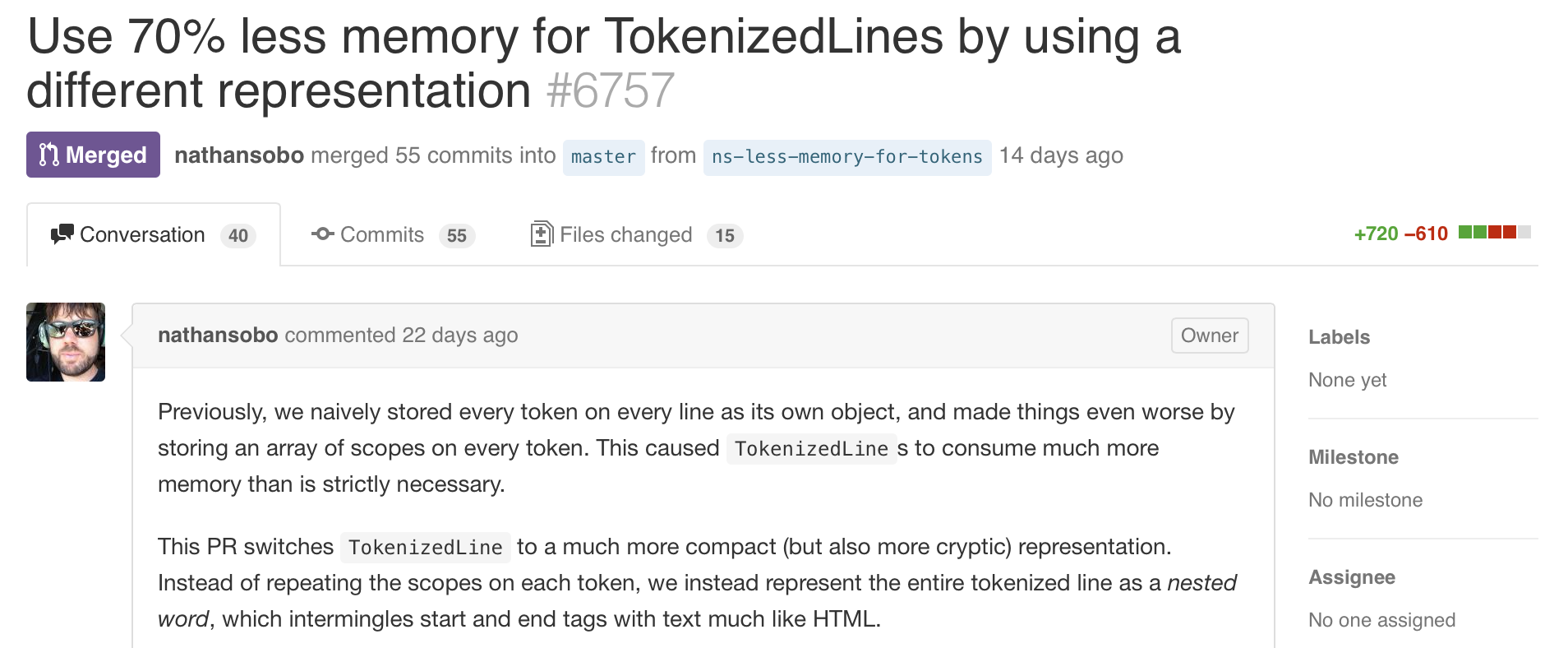
But click up from the commit’s page and take a look at the pull request and the general format becomes immediately familiar: it’s an extremely well-written and accessible discussion of the changes in that pull, complete with the analysis of the performance impact it will have. It effectively serves the same purpose as one of Peff’s individual commits.
Units of change
These are two extremes of viewing what the core unit of change is for the respective project. From Git’s perspective — likely because of the ease of use inside a mailing list approach — a single atomic commit makes most sense. From GitHub’s perspective, individual commits become less valuable because the atomic unit is the pull request. In both cases, more historical context on a change can be easily found by going back to the mailing list discussion or the pull request conversation.
I’m a product of GitHub culture, so I tend to throw a lot of commits into my projects. It leads to having more reference points to refer back to in the future. This is particularly true if I’m doing frontend work that requires some experimentation before I know what I’ll ultimately end up with.
Sometimes I’ll even deliberately push a commit and immediately revert it because I want a record of one possible experiment was. Rebasing out these “mistakes” down to a single commit makes it harder for me to see what I was playing with in the past. All of this leads to a dirty commit history, but I use pull requests to see that history.
That said, I’m extremely apathetic to this debate. Whatever makes the most sense for your team, go ahead and do it. Certainly successful projects can and have been built on either approach, or a hybrid of the two.
Limitations
Sometimes I wish version control had a bit better control over this. It might be interesting if Git had a new object that was below the Commit object — maybe a ExperimentalCommit that would get folded into a single Commit once it went through code review. That way, each developer could commit their scratchpad experimentations to mainline (so they can refer back to them in the future), but a separate commit history of code review could be generated and used as the “clean” history.
That said, I don’t actually want the added cognitive overhead of expanding Git’s simple object model, either, so I’m not seriously proposing this. It’s fun to envision a system where the two mindsets could live together a bit more harmoniously.
Food for thought for the next hot version control system, perhaps.
Anyway, what I’m trying to say is that git commit -m “unfuck this” shouldn’t necessarily be a capital crime. I think it’s a little more interesting than that. Look at the unit of change… that’s where the real work happens.