Organize with branches
A lot of the organizational problems surrounding deployment stems from
a lack of communication between the person deploying new code and the rest
of the people who work on the app with her. You want everyone to know the
full scope of changes you're pushing, and you want to avoid stepping on
anyone else's toes while you do it.
There's a few interesting behaviors that can be used to help with
this, and they all depend on the simplest unit of deployment: the branch.
Code branches
By "branch", I mean a branch in Git, or Mercurial, or whatever you
happen to be using for version control. Cut a branch early, work on it,
and push it up to your preferred code host (GitLab, Bitbucket, etc).
You should also be using pull requests, merge requests, or other code
review to keep track of discussion on the code you're introducing.
Deployments need to be collaborative, and using code review is a big part
of that. We'll touch on pull requests in a bit more detail later in this
piece.
Code Review
The topic of code review is long, complicated, and pretty specific to
your organization and your risk profile. I think there's a couple
important areas common to all organizations to consider, though:
-
Your branch is your responsibility. The companies
I've seen who have tended to be more successful have all had this idea
that the ultimate responsibility of the code that gets deployed falls
upon the person or people who wrote that code. They don't throw code
over the wall to some special person with deploy powers or testing
powers and then get up and go to lunch. Those people certainly should
be involved in the process of code review, but the most important part
of all of this is that you are responsible for your code. If
it breaks, you fix it… not your poor ops team. So don't break it.
-
Start reviews early and often. You don't need to
finish a branch before you can request comments on it. If you can open
a code review with imaginary code to gauge interest in the interface,
for example, those twenty minutes spent doing that and getting told
"no, let's not do this" is far preferable than blowing two weeks on
that full implementation instead.
-
Someone needs to review. How you do this can
depend on the organization, but certainly getting another pair of eyes
on code can be really helpful. For more structured companies, you
might want to explicitly assign people to the review and demand they
review it before it goes out. For less structured companies, you could
mention
different teams to see who's most readily available to help you
out. In either end of the spectrum, you're setting expectations that
someone needs to lend you a hand before storming off and deploying
code solo.
Branch and deploy pacing
There's an old joke that's been passed around from time to time about
code review. Whenever you open a code review on a branch with six lines of
code, you're more likely to get a lot of teammates dropping in and picking
apart those six lines left and right. But when you push a branch that
you've been working on for weeks, you'll usually just get people
commenting with a quick 👍🏼 looks good to me!
Basically, developers are usually just a bunch of goddamn lazy trolls.
You can use that to your advantage, though: build software using quick,
tiny branches and pull requests. Make them small enough to where it's easy
for someone to drop in and review your pull in a couple minutes or less.
If you build massive branches, it will take a massive amount of time for
someone else to review your work, and that leads to a general slow-down
with the pace of development.
Confused at how to make everything so small? This is where those
feature flags from earlier come into play. When my team of three rebuilt
GitHub Issues in 2014, we had shipped probably hundreds of tiny pull
requests to production behind a feature flag that only we could see. We
deployed a lot of partially-built components before they were "perfect".
It made it a lot easier to review code as it was going out, and it made it
quicker to build and see the new product in a real-world environment.
You want to deploy quickly and often. A team of ten could probably
deploy at least 7-15 branches a day without too much fretting. Again, the
smaller the diff, the more boring, straightforward, and stress-free your
deploys become.
Branch deploys
When you're ready to deploy your new code, you should always deploy
your branch before merging. Always.
View your entire repository as a record of fact. Whatever you have on
your master branch (or whatever
you've changed your default branch to be) should be noted as being the
absolute reflection of what is on production. In other words, you can
always be sure that your master branch is "good" and is a known state
where the software isn't breaking.
Branches are the question. If you merge your branch first into master
and then deploy master, you no longer have an easy way to determining what
your good, known state is without doing an icky rollback in version
control. It's not necessarily rocket science to do, but if you deploy
something that breaks the site, the last thing you want to do is have to
think about anything. You just want an easy out.
This is why it's important that your deploy tooling allows you to
deploy your branch to production first. Once you're sure that your
performance hasn't suffered, there's no stability issues, and your feature
is working as intended, then you can merge it. The whole point of having
this process is not for when things work, it's when things don't
work. And when things don't work, the solution is boring, straightforward,
and stress-free: you redeploy master. That's it. You're back to your known
"good" state.
Auto-deploys
Part of all that is to have a stronger idea of what your "known state"
is. The easiest way of doing that is to have a simple rule that's never
broken:
Unless you're testing a branch, whatever is deployed to production is
always reflected by the master branch.
The easiest way I've seen to handle this is to just always auto-deploy
the master branch if it's changed. It's a pretty simple ruleset to
remember, and it encourages people to make branches for all but the most
risk-free commits.
There's a number of features in tooling that will help you do this. If
you're on a platform like Heroku, they might have an option that lets you
automatically
deploy new versions on specific branches. CI providers like Travis CI
also will allow auto
deploys on build success. And self-hosted tools like Heaven and hubot-deploy — tools we'll
talk about in greater detail in the next section — will help you manage
this as well.
Auto-deploys are also helpful when you do merge the branch you're
working on into master. Your tooling should pick up a new revision and
deploy the site again. Even though the content of the software isn't
changing (you're effectively redeploying the same codebase), the SHA-1
does change, which makes it more explicit as to what the current known
state of production is (which again, just reaffirms that the master branch
is the known state).
Blue-green deploys
Martin Fowler has pushed this idea of blue-green deployment since his
2010
article (which is definitely worth a read). In it, Fowler talks about
the concept of using two identical production environments, which he calls
"blue" and "green". Blue might be the "live" production environment, and
green might be the idle production environment. You can then deploy to
green, verify that everything is working as intended, and make a seamless
cutover from blue to green. Production gains the new code without a lot of
risk.
One of the challenges with automating deployment is the cut-over itself,
taking software from the final stage of testing to live production.
This is a pretty powerful idea, and it's become even more powerful with
the growing popularity of virtualization, containers, and generally having
environments that can be easily thrown away and forgotten. Instead of
having a simple blue/green deployment, you can spin up production
environments for basically everything in the visual light spectrum.
There's a multitude of reasons behind doing this, from having disaster
recovery available to having additional time to test critical features
before users see them, but my favorite is the additional ability to play
with new code.
Playing with new code ends up being pretty important in the product
development cycle. Certainly a lot of problems should be caught earlier in
code review or through automated testing, but if you're trying to do real
product work, it's sometimes hard to predict how something will feel until
you've tried it out for an extended period of time with real data. This is
why blue-green deploys in production are more important than having a
simple staging server whose data might be stale or completely
fabricated.
What's more, if you have a specific environment that you've spun up
with your code deployed to it, you can start bringing different
stakeholders on board earlier in the process. Not everyone has the
technical chops to pull your code down on their machine and spin your code
up locally — and nor should they! If you can show your new live screen to
someone in the billing department, for example, they can give you some
realistic feedback on it prior to it going out live to the whole
company. That can catch a ton of bugs and problems early on.
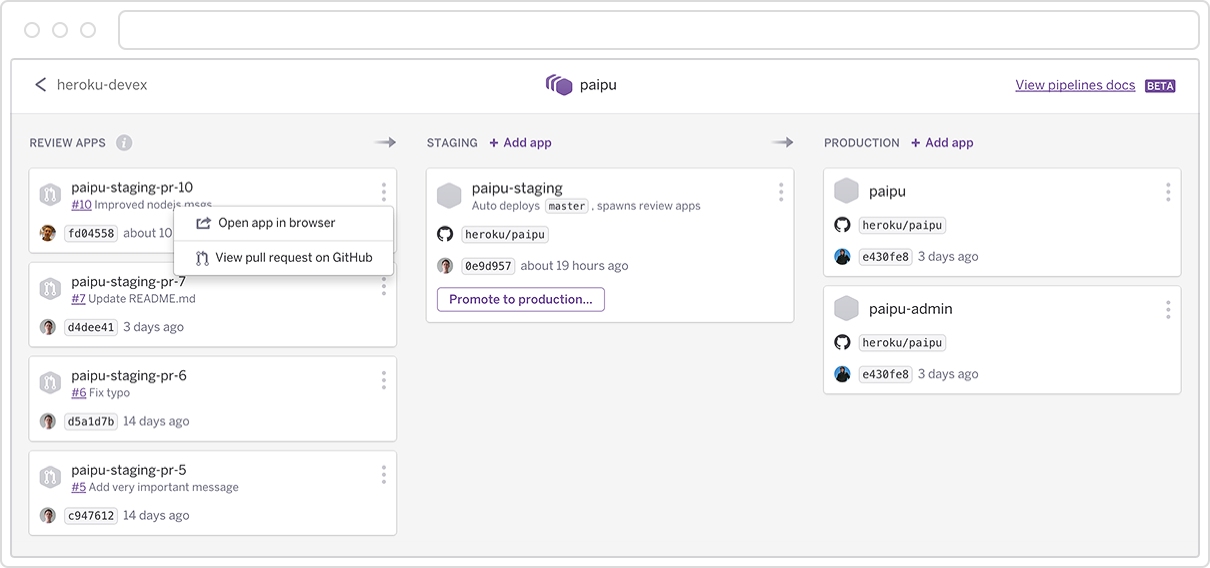
Whether or not you use Heroku, take
a look at how they've been building out their concept of "Review Apps"
in their ecosystem: apps get deployed straight from a pull request and can
be immediately played with in the real world instead of just being viewed
through screenshots or long-winded "this is what it might work like in the
future" paragraphs. Get more people involved early before you have a
chance to inconvenience them with bad product later on.